

※本記事は上記ドキュメントをベースに構成しています。
前回フェイルオーバグループを作成したので、現時点の構成を基に CLUSTERPRO のフェイルオーバについて理解を深めます。
 CLUSTERPRO構築備忘録①~NEC CLUSTERPRO X とは~
CLUSTERPRO構築備忘録①~NEC CLUSTERPRO X とは~
 CLUSTERPRO構築備忘録②~CLUSTERPRO X インストール手順~
CLUSTERPRO構築備忘録②~CLUSTERPRO X インストール手順~
 CLUSTERPRO構築備忘録③~フェイルオーバーグループの構築方法~
CLUSTERPRO構築備忘録③~フェイルオーバーグループの構築方法~
フェイルオーバする条件
NEC のサイトによると、フェイルオーバする条件は以下のとおりです。
(1)サーバーのシャットダウン/電源ダウン
(2)OS のパニック
(3)OS の部分的な障害(ディスク I/O のハングアップ)
(4)アプリケーションあるいはサービスの停止
(5)サービスのハングアップ ※エージェント製品による監視が必要です。
(6)NIC やパブリック LAN の異常検出
(7)CLUSTERPRO X サーバーモジュール自体の異常
(8)カスタム監視によるアプリケーションの監視
ただし、第1回でお話ししたとおり、これらは監視リソースを追加しなければフェイルオーバ条件とはなりません。現時点でのフェイルオーバ条件はハートビートが途絶した場合のみです。
監視リソースについて
ここで監視リソースについて深堀します。監視リソースとは具体的に以下の設定箇所になります。
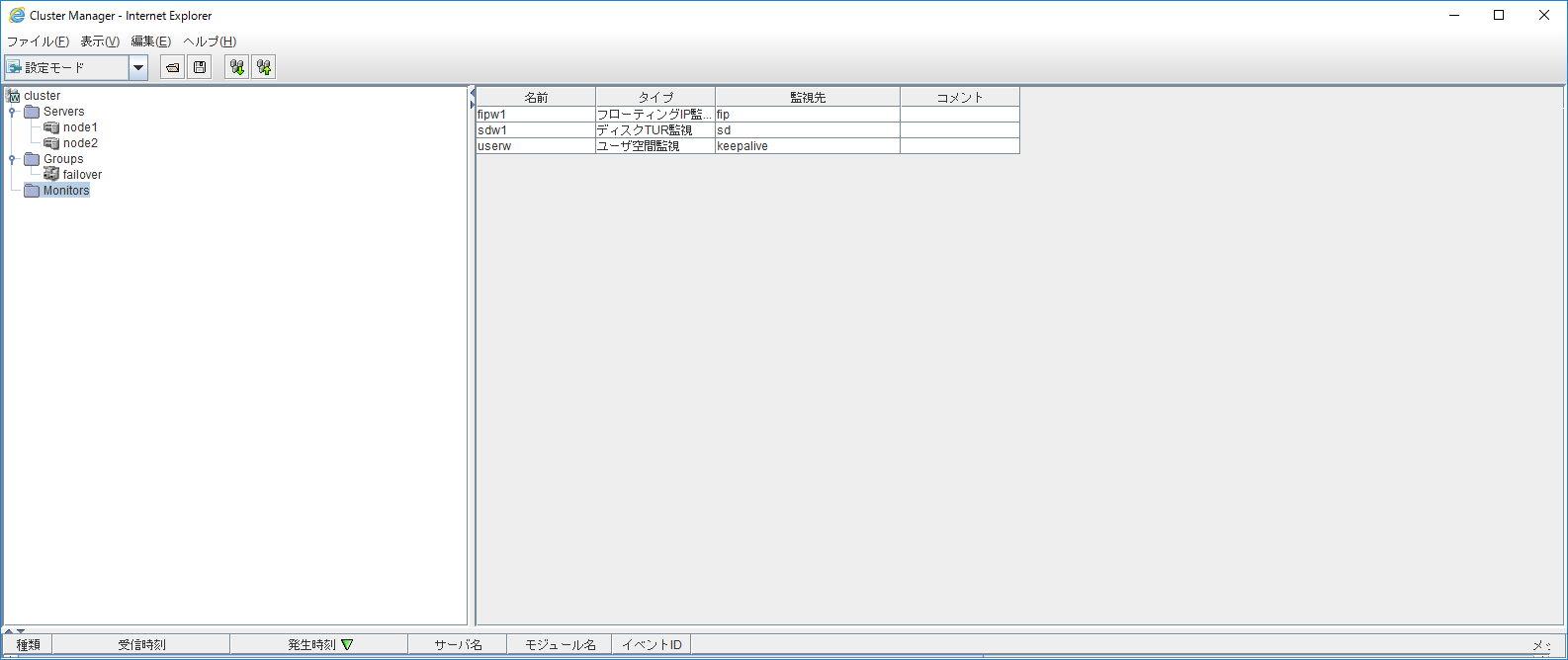
ここで認識してほしいことは、監視リソースが自動で作成されていることです。これによって、例えばディスクリソースにアクセスできなくなったらフェイルオーバが発生するようになります。
つまり先ほど「現状はハートビートが途絶した場合のみフェイルオーバする」と言ったのは嘘です。ディスクリソースとフローティング IP リソース、それからユーザ空間に障害が発生すると何らかの回復動作が始まります。
userw
第3回でクラスタを作成した際に自動で作成された監視リソースに「userw」というものがあります。これが何なのかもう一度おさらいします。
ユーザ空間監視リソースは、ユーザ空間のストールを監視するモニタリソースです。
監視開始時に keepalive タイマを起動し、以降、監視間隔ごとに keepalive タイマの更新を行います。ユーザ空間のストールによって、一定時間以上タイマの更新が行われなかった場合に異常を検出します。
リファレンスガイド P1087 より引用
OS 上でプログラムが起動された場合は OS の管理下の元、メモリ領域に展開します。このときのメモリ領域を『ユーザー空間』と呼びます。
まあ、「これだけは監視した方がいいでしょ」というおまじない的なやつですね。
グループリソースの「復旧動作」とモニタリソースの「回復動作」の違い
少し混乱しがちなのが、グループリソースの「復旧動作」とモニタリソースの「回復動作」の違いです。これらはどちらもフェイルオーバを発生させるトリガーとすることができますが、以下のように判定のタイミングが異なります。
「グループリソースの”復旧動作”とモニタリソースの”回復動作”の違い」について、どちらでも自動フェイルオーバを発生させることができるようですが判定のタイミングが異なるということでしょうか。復旧動作の方は「起動/停止時」、モニタリソースは「監視タイミングに準ずる」ということですか?
はい、お客様のご認識の通りです。グループリソースの”復旧動作”は、活性/非活性時に異常を検出(失敗)した際に行われる動作です。モニタリソースの”回復動作”は、監視処理にて異常を検出した際に回復対象に対して行われる動作です。
ハートビートの設定
しつこいほど説明してきましたが、CLUSTERPRO X のフェイルオーバ条件は「ハートビートの途絶」と「監視リソースの異常検知」、「グループリソースの活性/非活性異常」です。ハートビートの設定変更箇所についても触れておきます。
builder でクラスタ名を右クリックから「プロパティ」を開きます。
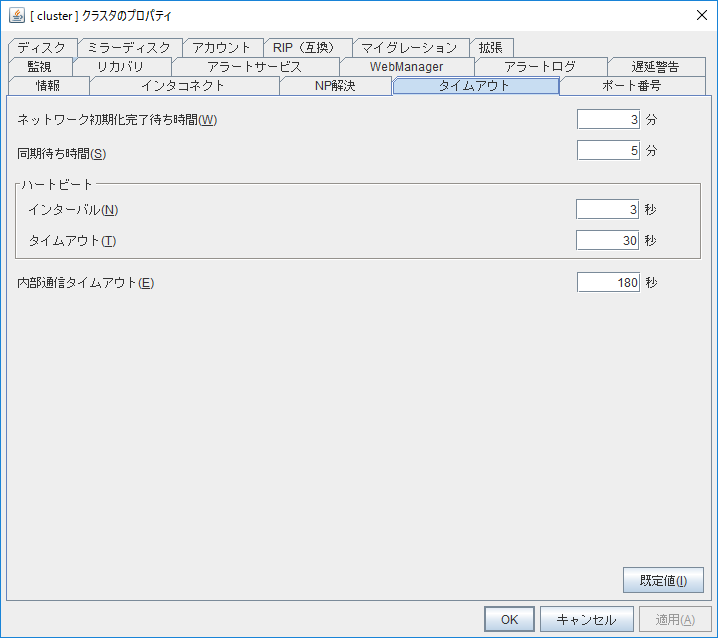
「タイムアウト」タブでハートビートのインターバルやタイムアウト時間を変更できます。
フェイルオーバテスト
予備知識はもう十分かと思いますので、実際にいくつかテストを行ってみます。期待通りに動くかをイメージしてください。
サーバーのシャットダウン/電源ダウン
下図のようにホスト1号機がアクティブになっている状態で、1号機をシャットダウンしてみます。シャットダウンは Cluster WebUI からではなくホストから実行します。
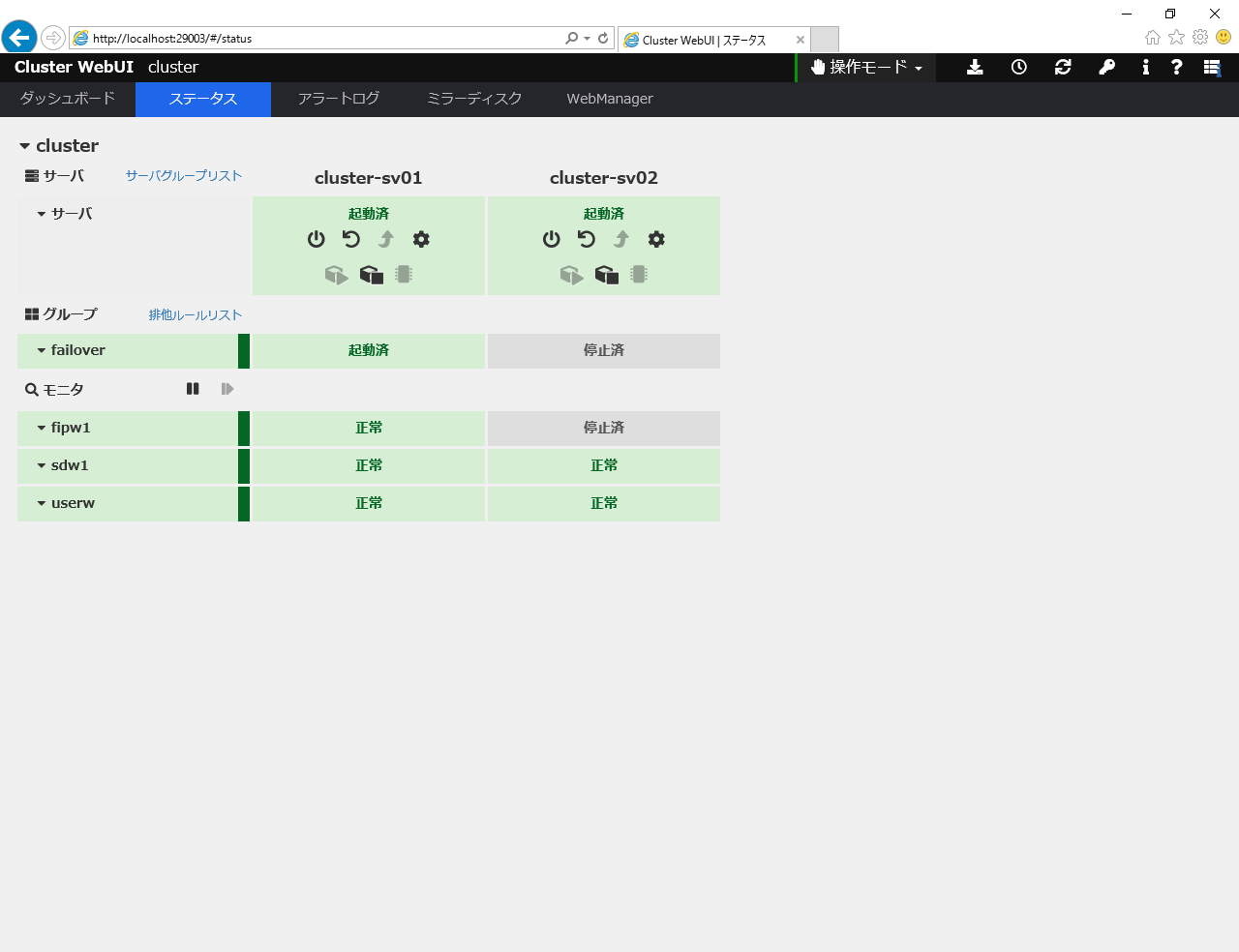
シャットダウン前
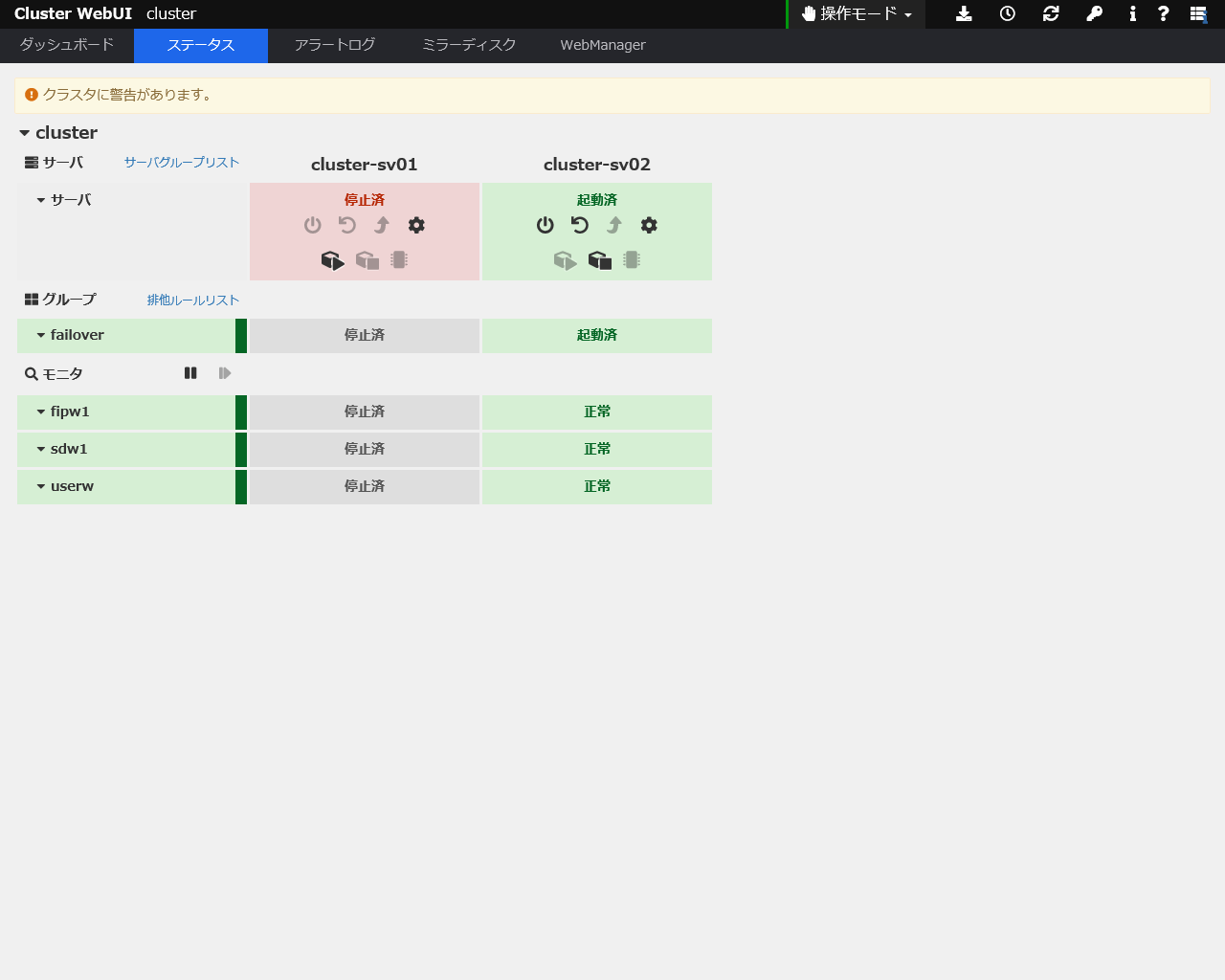
シャットダウン後
上図のように、1号機がシャットダウンされると2号機にリソースが引き継がれていることがわかります。
1号機を起動すると下図のようになります。フェイルバックはデフォルトのまま「手動」にしているため、自動で戻りません。
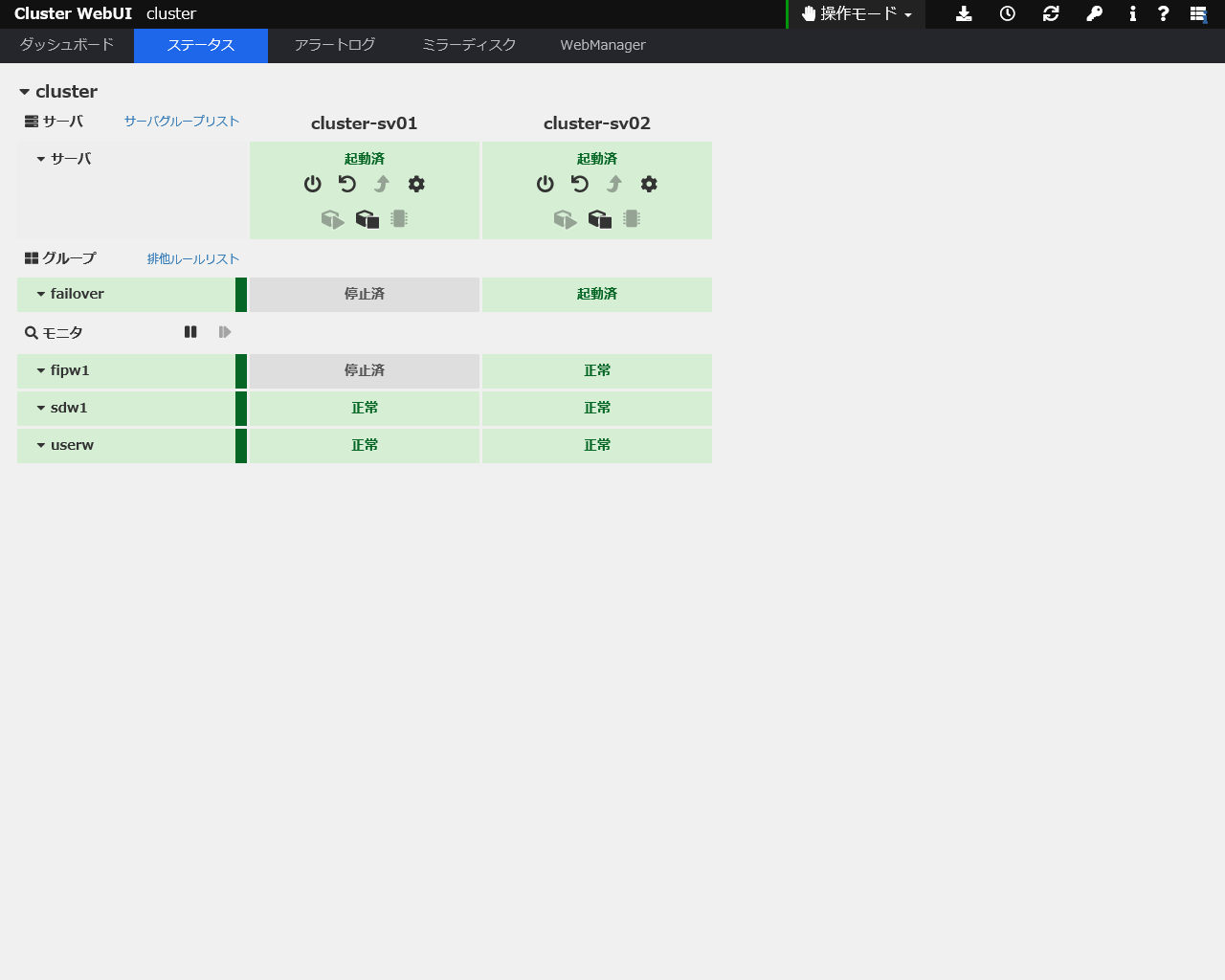
手動でフェイルバックを実行すると元と同じ状態になります。
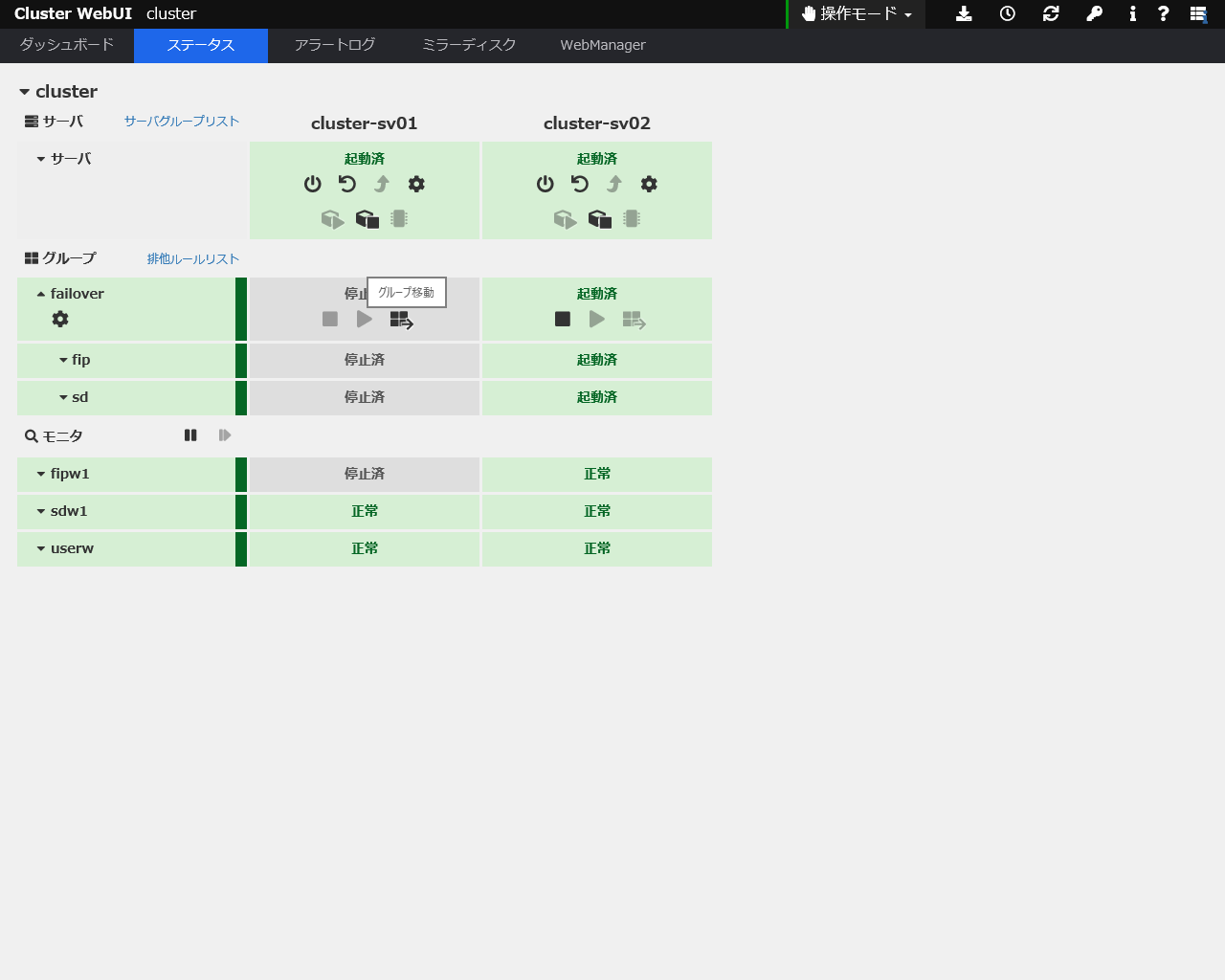
「グループ」の「グループ移動」をクリック
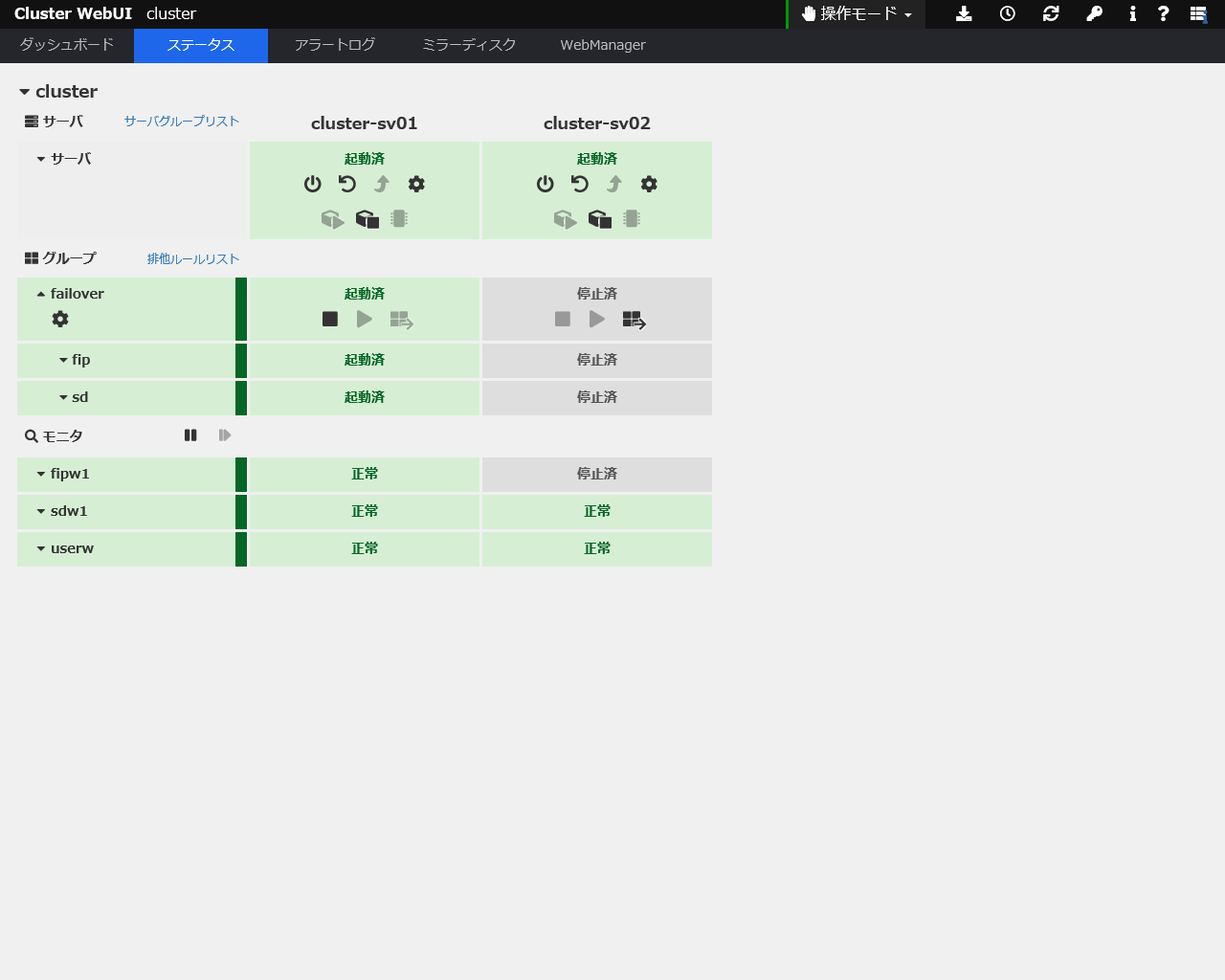
リソースが移ります
OSのパニック
まず、Windows で疑似的にシステムエラーを発生させるための下準備を行います。
参考サイト:メモリ ダンプ ファイルを生成する方法について | Technet
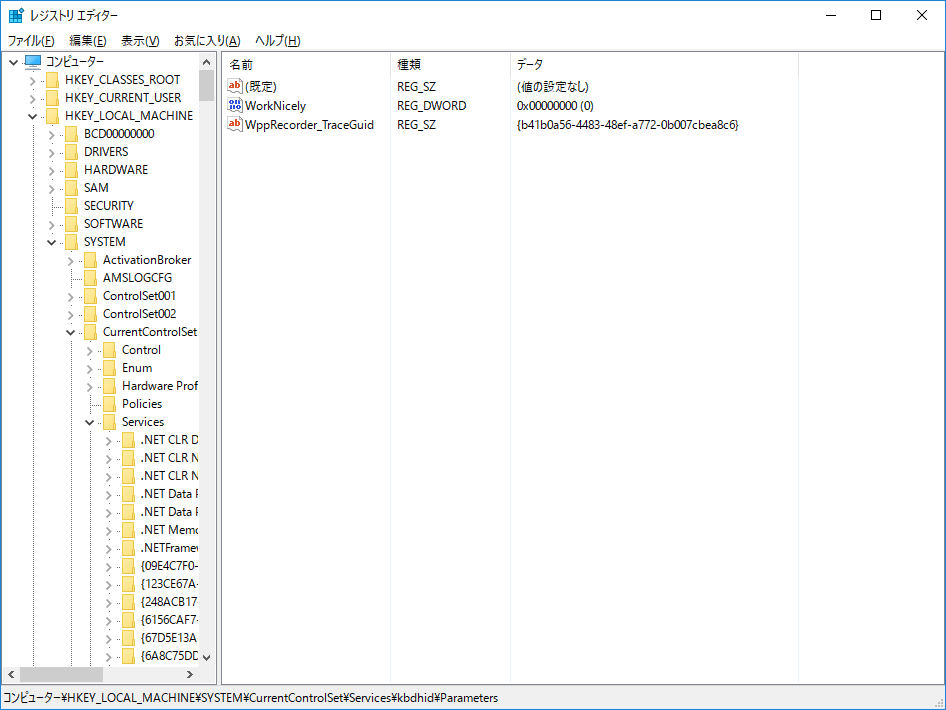
レジストリエディタで以下の場所まで潜って下さい。
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\kbdhid\Parameters
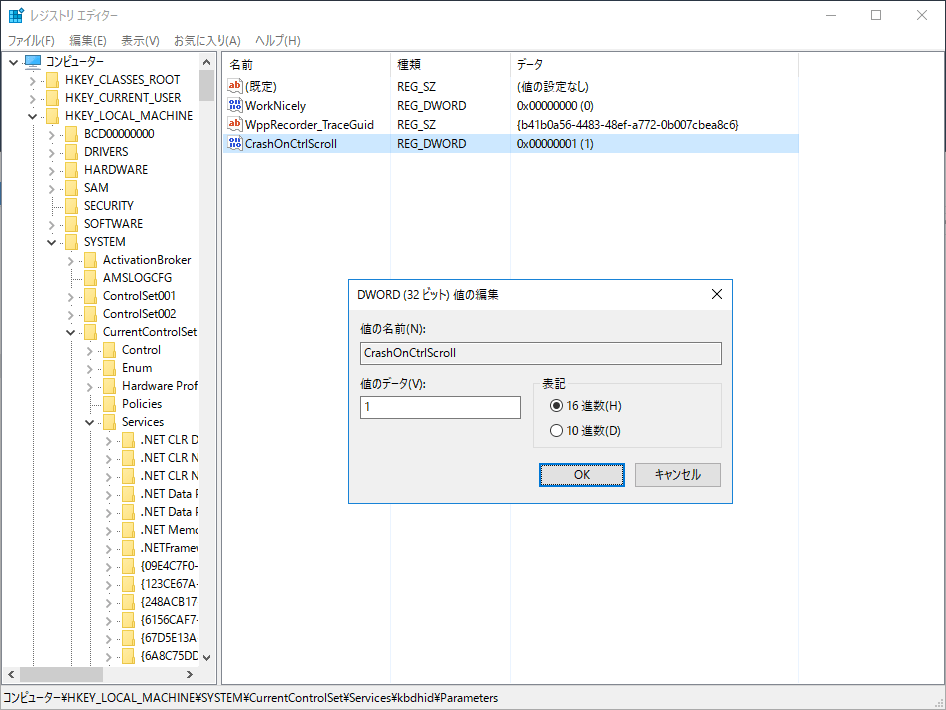
そこに「CrashOnCtrlScroll」を REG_DWORD(DWORD(32ビット)値) 形式で作成し、値に「1」を設定してください。
これでシステムエラー発生の準備は完了です。現状は下図のようにホスト1号機がアクティブです。

1号機がアクティブ
1号機で右CTRL を押下したまま Scroll Lock を2回押します。左CTRL だと反応しないので注意してください。そうすると即座に青い画面になってしばらくした後に再起動されます。
下図のように、1号機がシステムエラーで再起動すると2号機にリソースが引き継がれていることがわかります。
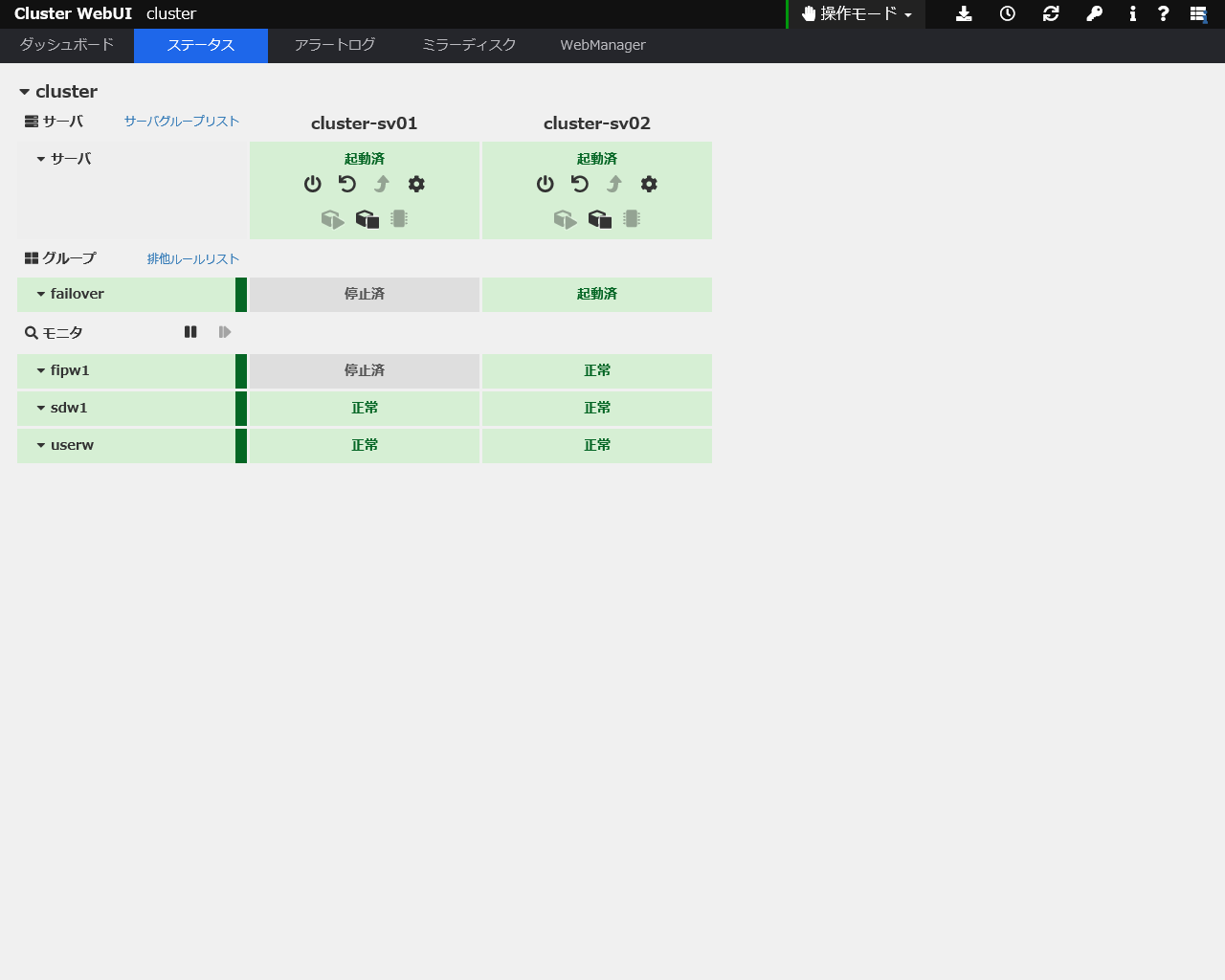
システムエラー発生後
NIC やパブリック LAN の異常検出
アクティブな1号機の LAN ケーブルを続々と抜いてみましょう。まずはパブリック LAN 用の ケーブルを抜いてみます。

1号機がアクティブ
ハートビートはハートビート専用 LAN で継続しているため、フェイルオーバはしませんでした。
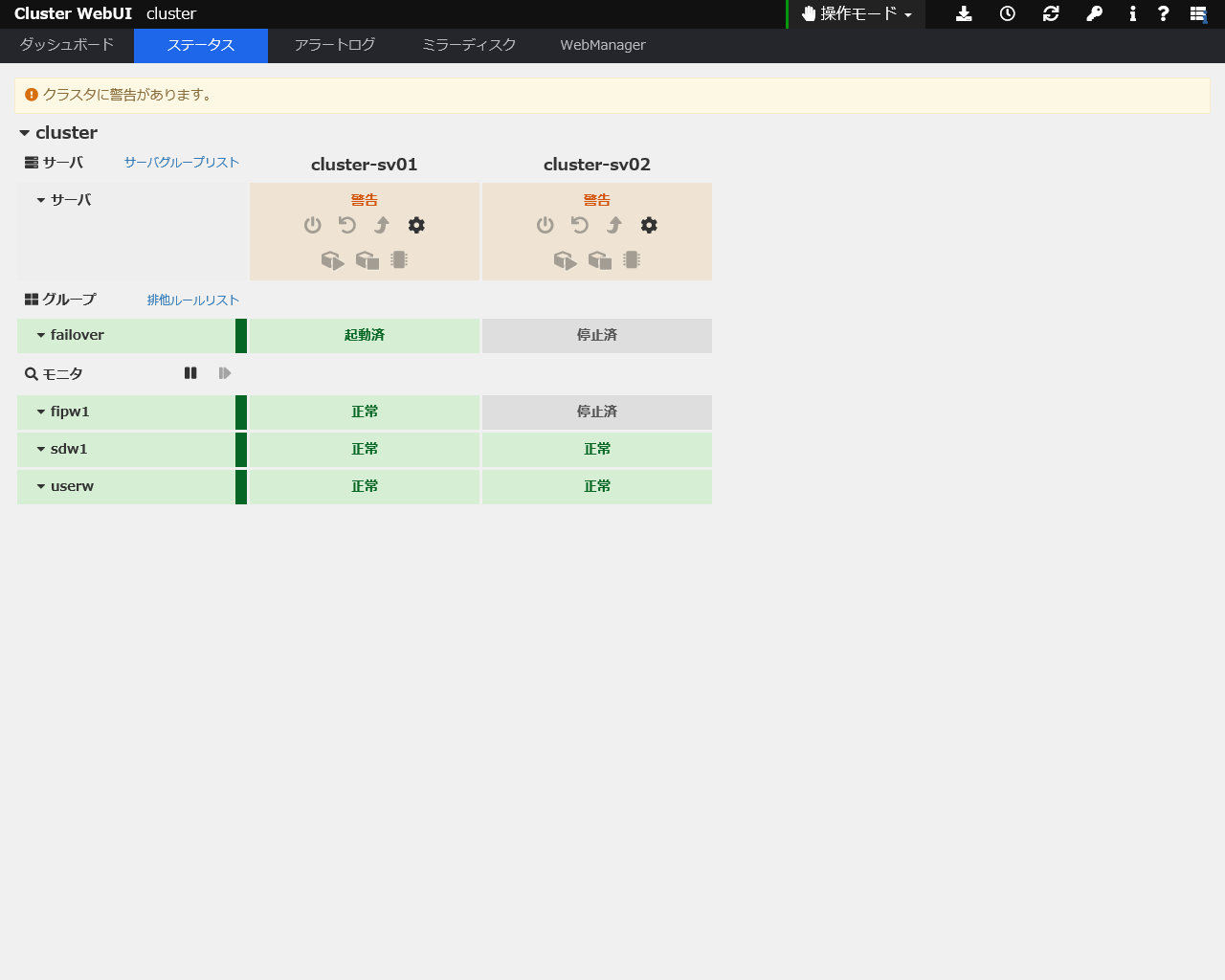
フェイルオーバせず
パブリック LAN は再接続して元の状態にし、ハートビート LAN 用のケーブルを抜いてみます。
こちらもパブリック LAN でハートビートは継続しているため、フェイルオーバは発生しません。
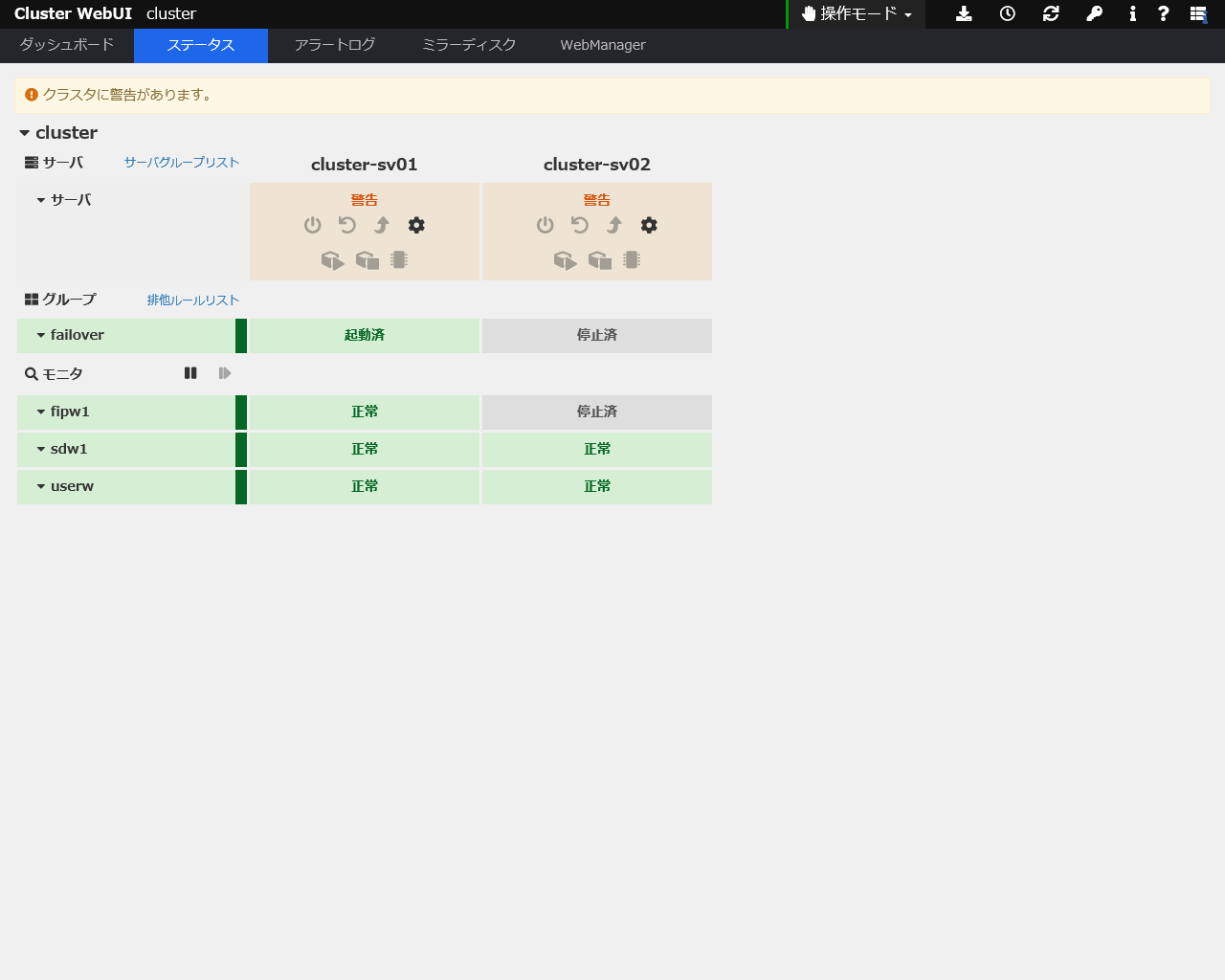
フェイルオーバせず
最後に1号機の全てのインタコネクト(パブリック,ハートビート)用ケーブルを抜いてみます。そうすると、スタンバイ側の2号機がシャットダウンしました。
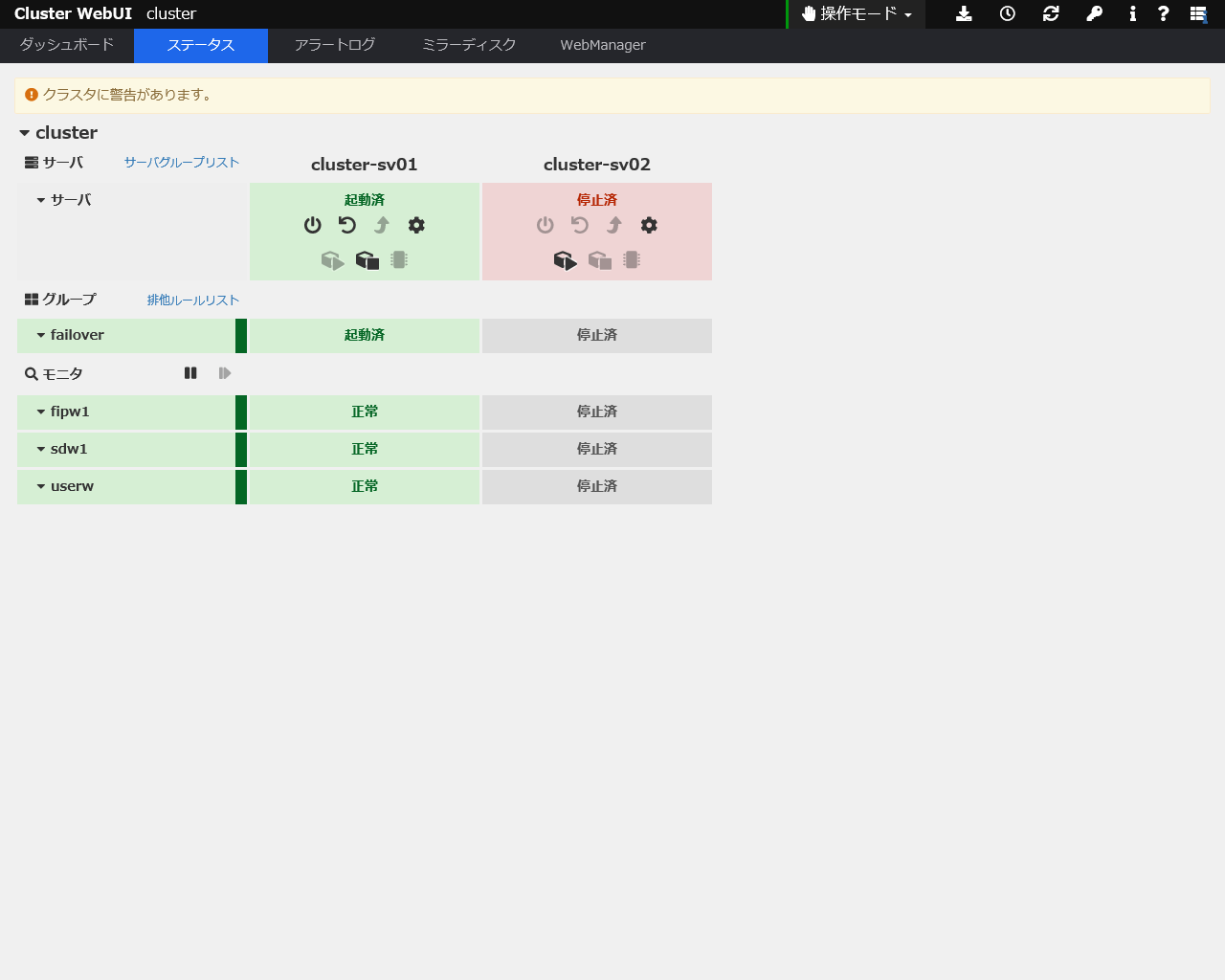
2号機が緊急シャットダウン
ネットワークパーティションについて
結局ケーブルを抜いた場合フェイルオーバは発生しませんでした。原因はというと、ネットワークパーティション解決によるものです。思い出してください。ハートビートが途絶した場合、CLUSTERPRO はネットワークパーティション解決を行います。改めて、ネットワークパーティションとは以下のような状態を指します。
サーバ間をつなぐすべてのインタコネクトが切断されると、ハートビートによる死活監視だけではサーバのダウンと区別できません。この状態でサーバダウンとみなし、フェイルオーバ処理を実行し、複数のサーバでファイルシステムを同時にマウントすると、共有ディスク上のデータが破壊されてしまいます。 このような問題を「ネットワークパーティション症状」またはスプリットブレインシンドローム(Split-brain-syndrome) と呼びます。
今回は NP 解決の結果、マスターサーバ以外のサーバが緊急シャットダウンしたということです。
共有ディスクが正常な状態で全てのネットワーク通信路に障害が発生した場合は、ネットワークパーティションを検出して、マスタサーバ及びマスタサーバと通信できるサーバがフェイルオーバ処理を実施します。それ以外のサーバは全て緊急シャットダウンします。
CLUSTERPRO の動きを見るのはこのへんにしておきます。次回は Oracle をインストールします。



情報ありがとうございます。
CLIで正副を入れ替えたりはできるのでしょうか?
その場合 どのようなコマンドで制御できますか?